Scraping IMDB top 250 movies in Python
Web crawling is much easier than it sounds like. I just started to use Python for about 3 weeks and now, with the help of a few modules, I’m able to start to scrape IMDB (static) pages. So … it’s not that hard. Why static pages? You will find it much more difficult if the web page you are scraping is dynamic, which means contents of interest are return values from some js function. Of course there are always solutions. However, standing on a beginner point of view I will skip that part for now.
Step by Step
Generally speaking, there are 3 steps to scrape a webpage:
- Request to visit that particular webpage, just like what your browser does, and download the HTML contents into your environment. I used
requestsmodule to accomplish this.urllib2,urllib3are also available choices. BeautifulSoupmodule can be used to parse HTML contents. In addition to that, it provides very powerful and useful functions, searching through thesoupobject to match for text and HTML tags within the page.- Extract what you want from the webpage and download/store them for further analysis.
Here I’m going to present the example of scraping IMDB top 250 movies and want to visualize the count distribution over time.
First of all, let’s import some modules and set up the working directory. Besides, I also want to check the current encoding system because, as you may imagine, there are a few top 250 movie names are not English.
"""
Created on Mon Apr 18, 2016
@author: Honglei
Purpose: To scrapy top 250 movies in IMDB and visualize the frequency varying time
"""
import urllib2
import os
import requests
import re
from bs4 import BeautifulSoup
import sys
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
os.getcwd() # current working directory
os.chdir('/Users/Honglei/Desktop') # change current working directory
# get the current encoding
type = sys.getfilesystemencoding()
I downloaded the HTML texts as page and created the soup object. Open the URL link below and view the page source (Windows try Ctrl+U, I strongly suggest Chrome and its associated developer tools)
You may also run print soup.prettify() to see the nicer formatted HTML.
# request the webpage
req = requests.get("http://www.imdb.com/chart/top?pf_rd_m=A2FGELUUNOQJNL&pf_rd_p=2417962742&pf_rd_r=0M85G1V8JHW928EHBETF&pf_rd_s=right-4&pf_rd_t=15506&pf_rd_i=moviemeter&ref_=chtmvm_ql_3")
page = req.text
soup = BeautifulSoup(page, 'html.parser')
#print soup.prettify()
After a little bit analysis on the strings, I found out that all movie information are under <td class="titleColumn"> and the it follows the pattern:
<a href="url_link" title = "People_Names" Movie_Names </a><span class="secondaryInfo">(Year)</span>
What I want to extract are the [Movie_Names] and [Year].
# get top 250 movie names and years, may take ~30 seconds
movie_names = []
movie_year = [0] * 250
j = 0
for i in range(250):
content = str(soup.findAll('td', {'class':'titleColumn'})[i])
content = content.decode("UTF-8").encode(type)
name = re.findall ( '>(.*?)</a>', content)
movie_names.insert(len(movie_names), name)
year = str(soup.findAll('span', {'class':'secondaryInfo'})[i])
movie_year[i] = int(re.findall(r"\(([0-9_]+)\)", year)[0])
# keep track of the progress
print('We now have ' + str(j) + ' movies')
j = j+1
print movie_names
print movie_year
Export the movie names into txt file and plot.
# export to the text file
open("top250names.txt", "w").write("\n".join(("\t".join(item)) for item in movie_names))
######## plot the count by time #########################
# compute the frequency table
y = np.bincount(movie_year)
ii = np.nonzero(y)[0]
out = zip(ii, y[ii])
# crete a dataframe
df = pd.DataFrame(out, columns = ['Year', 'Freq'], index = ii)
# drop the first Year column since I already assign valid index
df.drop(df.columns[0], axis = 1)
# plot
plt.plot(ii, df['Freq']);
Conclusion
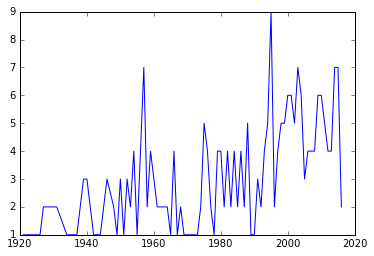
OK, story! It’s obvious we don’t get evenly quality movies every year. Moreover, what’s often been observed is that art masters tend to come in batches and go in batches. That’s why you see there are two peaks around year 1958 and 1994 but leaving other years flat. Fortunately there seems to be a lifting trend after 2000. Or does it only suggest IMDB users become easily pleased in the past 15 years?