Build a vanilla movie recommender with Spark
This is a lab originally from the edX course: Big Data Analysis with Apache Spark where I learned how to construct a machine learning pipeline with Spark. There I’ve added with minor modifications to code about parameters tuning. In this post, you are expected to learn to build a movie recommender using collaborative filtering with Spark’s Alternating Least Squares (ALS) implementation, based upon the MovieLens small dataset. Note that this is just a vanilla version of movie recommender, with a lot of potential improving opportunities. I will talk about it later.
![]()
![]()
Download Data
Firstly, let’s clarify the scale of this project. For the sake of educational purpose, I only used the small movie review dataset here, which contains 100,000 ratings applied to 9,000 movies by 700 users. Go there to check out the data by yourself.
import os
import urllib.request
import zipfile
import numpy as np
dataset_url = 'http://files.grouplens.org/datasets/movielens/ml-latest-small.zip'
datasets_path = '/Users/Honglei/Desktop/'
small_dataset_path = os.path.join(datasets_path, 'ml-latest-small.zip')
small_f = urllib.request.urlretrieve (dataset_url, small_dataset_path)
with zipfile.ZipFile(small_dataset_path, "r") as z:
z.extractall(datasets_path)
Parsing Data
small_ratings_file = os.path.join(datasets_path, 'ml-latest-small', 'ratings.csv')
# import PySpark modules
import findspark
findspark.init()
from pyspark.sql import SparkSession
from pyspark.sql.types import *
from pyspark.sql.functions import *
from pyspark.ml.evaluation import RegressionEvaluator
from pyspark.ml.recommendation import ALS
from pyspark.sql import functions as F
One thing I would like point out is that my spark version is 2.2.0 therefore some modules imports are probably only valid for spark version 2.X. If you are using 1.X, you may have some errors when running through the codes above. Another note I would like to add is the ALS class that I imported there is actually coming from pyspark.ml.recommendation not pyspark.mllib.recommendation. Syntax is a bit different but performance is generally the same.
Let’s continue to load data into a dataframe.
spark = SparkSession \
.builder \
.appName("Movie recommendation") \
.getOrCreate()
ratings_df = spark.read.option("header", "true").csv(small_ratings_file)
We only select userId, movieId and rating columns and check out the data schema.
ratings_df = ratings_df.select(col("userId"), col("movieId"), col("rating"))
print(ratings_df.schema)
Why do we care about the schema? Because we want to make sure data has the right data types as required before feeding into any machine learning algorithm.
You should get the following outputs:
StructType(List(StructField(userId,StringType,true),
StructField(movieId,StringType,true),
StructField(rating,StringType,true)))
Then we want to filter out movies that have very few (<10) reviews to forcefully restrict sparsity.
movie_ids_with_avg_ratings_df = ratings_df.groupBy('movieId').\
agg(F.count(ratings_df.rating).alias("count"), F.avg(ratings_df.rating).alias("average"))
movies_with_10_ratings_or_more = movie_ids_with_avg_ratings_df.filter("count>=10")
movies_with_10_ratings_or_more = movies_with_10_ratings_or_more.sort(movies_with_10_ratings_or_more.average, ascending = False)
print ('Movies with top 5 highest ratings:')
movies_with_10_ratings_or_more.show(5, truncate = False)
# merge with ratings_df
ratings_df = movies_with_10_ratings_or_more.join(ratings_df, "movieId", "inner")

Having check the data schema previously, we need to change the String type to numeric type as required by pyspark.ml.recommendation.ALS.
ratings_df = ratings_df.select(col("userId"), col("movieId"), col("rating"))
ratings_df = ratings_df.withColumn("rating", ratings_df["rating"].cast(DoubleType()))
ratings_df = ratings_df.withColumn("movieId", ratings_df["movieId"].cast(DoubleType()))
ratings_df = ratings_df.withColumn("userId", ratings_df["userId"].cast(DoubleType()))
ratings_df.cache()
assert ratings_df.is_cached
Split data into training, validation and testing
You know the drill … We hold out 60% for training, 20% for validation, and leave 20% for testing.
seed = 2017
(split_60_df, split_a_20_df, split_b_20_df) = ratings_df.randomSplit([0.6,0.2,0.2], seed)
# cache these datasets for performance
training_df = split_60_df.cache()
validation_df = split_a_20_df.cache()
test_df = split_b_20_df.cache()
print('Training: {0}, validation: {1}, test: {2}\n'.format(training_df.count(), \
validation_df.count(), \
test_df.count()))
You should expect Training: 48985, validation: 16603, test: 16327
Baseline Model
Wait a second, let’s check out how does the baseline model perform! Without a baseline number to compare against, the metric of choice RMSE is pointless.
# RMSE evaluator using the label and predicted columns
reg_eval = RegressionEvaluator(predictionCol = "prediction", labelCol = "rating", metricName = "rmse")
training_avg_rating = training_df.agg(avg(training_df.rating)).collect()[0][0]
# add a column with the average rating
test_for_avg_df = test_df.withColumn('prediction', F.lit(training_avg_rating))
# get RMSE
test_avg_RMSE = reg_eval.evaluate(test_for_avg_df)
print("The baseline RMSE is {0}".format(test_avg_RMSE))
The baseline RMSE is ~ 1.032
Collaborative Filtering and ALS
Collaborative filtering is commonly used for recommender systems, which is a method of making automatic predictions (filtering) about the interests of a user by collecting preferences or taste information from many users (collaborating). The underlying assumption of the collaborative filtering approach is that if a person A has the same opinion as a person B on an issue, A is more likely to have B’s opinion on a different issue x than to have the opinion on x of a person chosen randomly.
spark.ml currently supports model-based collaborative filtering, in which users and products are described by a small set of latent factors that can be used to predict missing entries. spark.ml uses the alternating least squares (ALS) algorithm to learn these latent factors. The implementation in spark.ml has the following parameters:
rankis the number of latent factors in the model.iterationsis the number of iterations to run.regParamspecifies the regularization parameter in ALS.
Default parameters ml.recommendation.ALS
class pyspark.ml.recommendation.ALS(self,
rank=10, maxIter=10, regParam=0.1, numUserBlocks=10, numItemBlocks=10,
implicitPrefs=false, alpha=1.0, userCol="user", itemCol="item", seed=None,
ratingCol="rating", nonnegative=false, checkpointInterval=10,
intermediateStorageLevel="MEMORY_AND_DISK", finalStorageLevel="MEMORY_AND_DISK",
coldStartStrategy="nan")
Since not all users have rated all movies, we do not know all of the entries in this matrix, which is precisely why we need collaborative filtering. For each user, we have ratings for only a subset of the movies. With collaborative filtering, the idea is to approximate the ratings matrix by factorizing it as the product of two matrices: one that describes properties of each user (shown in green), and one that describes properties of each movie (shown in blue).
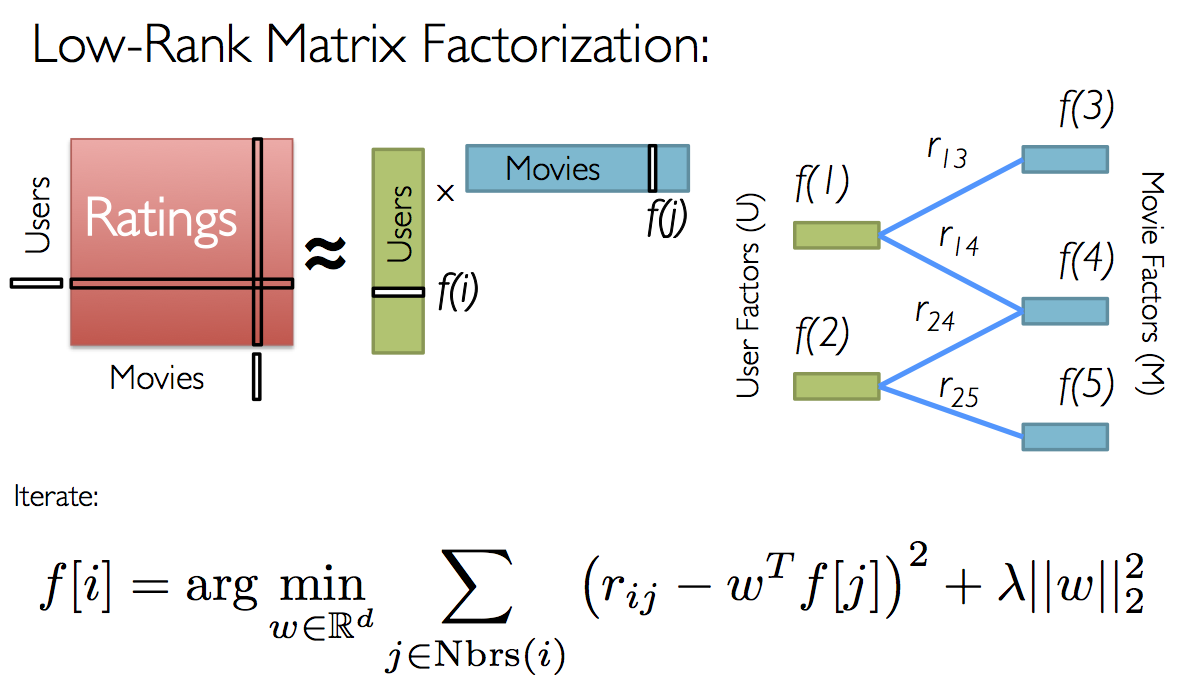
We optimize the objective function via ALS, basically updating \(f[i]\) and \(f[j]\) in an alternative fashion.
Let’s do a grid search for the best parameters, testing on the validation dataset.
def train_ALS(rank, maxit, reg, train_df, test_df, seed = 2017):
als = ALS(maxIter = maxit,
regParam = reg,
rank = rank,
userCol = "userId",
itemCol = "movieId",
ratingCol = "rating",
coldStartStrategy = "drop")
# set the parameters for the method
als.setSeed(seed)
# Create the model with these parameters.
model = als.fit(train_df)
# Run the model to create a prediction. Predict against the validation_df.
predict_df = model.transform(test_df)
error = reg_eval.evaluate(predict_df)
# In-sample error
predict_in_df = model.transform(train_df)
in_error = reg_eval.evaluate(predict_in_df)
# print
print ("Using number of ranks = ", rank)
print ("Using number of iterations = ", maxit)
print ("Using Reg para = ", reg)
print ("Training dataset RMSE = ", in_error, '\n')
print ("Validation dataset RMSE = ", error, '\n')
return(error)
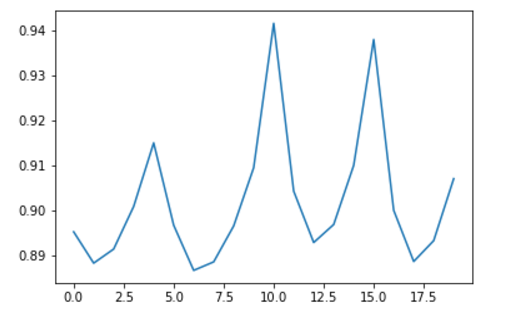
numIterations = [5, 10]
ranks = [2, 4]
regs = list(np.arange(0.05, 0.3, 0.05))
RMSE_results = []
for rank in ranks:
for maxit in numIterations:
for reg in regs:
RMSE_results.append(train_ALS(rank = rank, maxit = maxit, reg = reg, \
train_df = training_df, test_df = validation_df))
import matplotlib.pyplot as plt
%matplotlib inline
plt.plot(RMSE_results);
Alert: it will take a WHILE.
Pick the best parameters and test on the testing dataset!
test_error = train_ALS(rank = 2, maxit = 10, reg = 0.1,\
train_df = training_df, test_df = test_df)
print("The ALS RMSE is {0}".format(test_error))
Compared with the baseline RMSE 1.032, our model generated RMSE 0.8709 on the same testing dataset.
Recommend myself some movies, go!
The first thing is to find the movieId and movie title mapping so that I can give out my ratings to movies that I have watched!
movies_file = os.path.join(datasets_path, 'ml-latest-small', 'movies.csv')
movies = spark.read.option("header", "true").csv(movies_file)
movies_titles = movies.rdd.map(lambda x: (int(x[0]),x[1]))
movies_df = movies.drop('genres').withColumnRenamed('movieId', 'ID')
You can even do a simple query like this (printing out all movie titles contain love), isn’t spark straightforward enough?
my_movies = movies_df.filter("title like '%love%'")
Now I need to rate some movies for the myself. Let’s use the user ID 0 for me as this is not assigned in the MovieLens dataset.
from pyspark.sql import Row
my_user_id = 0
# The format of each line is (userId, movieId, rating), rating scale is 0-5
my_ratings = [
(0,260,1), # Star Wars (1977)
(0,60950,5), # Vicky Cristina Barcelona (2008)
(0,79132,5), # Inception (2010)
(0,86882,5), # Midnight in Paris (2011)
(0,318,5), # Shawshank Redemption, The (1994)
(0,215,5), # Before Sunrise (1995)
(0,8638,5), # Before Sunset (2004)
(0,296,4), # Pulp Fiction (1994)
(0,858,4) , # Godfather, The (1972)
(0,33645,5), # Carol (2015)
(0,4993,1), # Lord of the Rings: The Fellowship of the Ring, The (2001)
(0, 995,4) # Beautiful Mind, A (2001)
]
my_ratings_df = spark.createDataFrame(my_ratings, ['userId','movieId','rating'])
Add my ratings to the training dataset so that the model will incorporate my preferences.
training_with_my_ratings_df = training_df.unionAll(my_ratings_df)
als = ALS(maxIter = 10, regParam = 0.1, rank = 2,
userCol = "userId", itemCol = "movieId",
ratingCol = "rating",
coldStartStrategy = "drop")
als.setSeed(2017)
final_model = als.fit(training_with_my_ratings_df)
# a list of my rated movie IDs
my_rated_movie_ids = [x[1] for x in my_ratings]
# filter out the movies I already rated.
not_rated_df = movies_df.filter(~ movies_df['ID'].isin(my_rated_movie_ids))
# rename the "ID" column to be "movieId", and add a column with my_user_id as "userId".
my_unrated_movies_df = not_rated_df.withColumn("userId", F.lit(my_user_id)).withColumnRenamed("ID","movieId")
my_unrated_movies_df = my_unrated_movies_df.withColumn("movieId", my_unrated_movies_df["movieId"].cast(DoubleType()))
# use my_rating_model to predict ratings for the movies that I did not manually rate.
predictions = final_model.transform(my_unrated_movies_df)
predicted_highest_rated_movies_df = predictions.sort(predictions.prediction, ascending = False)
print ('My 5 highest rated movies as predicted:')
predicted_highest_rated_movies_df.select('title').show(5, truncate = False)
