Get Started with Dask
Dask is simply awesome. If you are looking for Spark alternatives that are light-weight, simple, easy to set-up, native to Python, and do its job (i.e distributed computing) well without changing much of your existing Python codes (in numpy or pandas or whatever), you absolutely should give Dask a try!
First and foremost, the ultimate guide you should refer to is the official doc.
Local set-up
It’s super easy to set-up a local distributed cluster using Dask.
from dask.distributed import Client
client = Client(n_workers=4)
Performance benchmark
Data
Following a classic example in Dask’s tutorials, I will use this NYC Yellow Taxi Trips Dataset to benchmark performance. This is a medium-sized data set which probably cannot fit into RAM but can fit into most machines’ physical storage. In the flip side, if the data can fit into the RAM then probably you don’t need Dask or tooling to do distributed computing. Let’s download 2019 Yellow Taxi Trip Records Oct, Nov, Dec data into the local machine and check the memory footprint first.
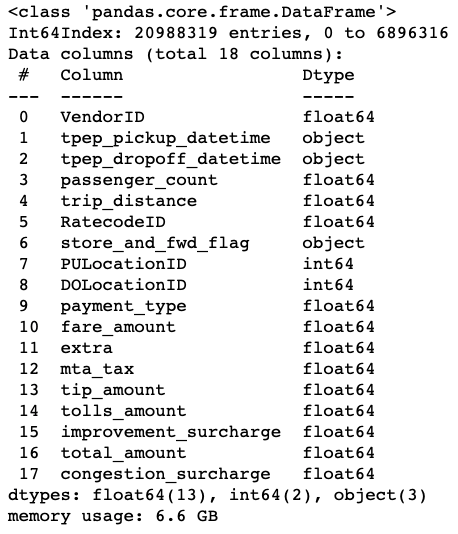
Raw Pandas
We are interested in the average tip amount per passenger_count.
df.groupby("passenger_count").tip_amount.mean()

Local 4-core
Dask is not much different than Python process or threads parallel computing library that you may already use in the past, such as multiprocessing.
However, it provides great convenience setting up computing graphs, scheduling tasks, parallel computing optimization under the hood. The computing mechanism also looks similar to Spark, such as lazy evaluation, scaling up to massive number of cores in cloud etc.

# A simple computation over 6.6G data
%%time
import dask.dataframe as dd
df = dd.read_csv("~/Documents/GitHub/data/Taxi/yellow_tripdata_2019-*.csv",
dtype={'RatecodeID': 'float64',
'VendorID': 'float64',
'passenger_count': 'float64',
'payment_type': 'float64',
'tolls_amount': 'float64',
'store_and_fwd_flag': 'object'
})
Note that Dask estimates the data types with a small sample of data to stay efficient, so a good practice is to specify data types during read_csv().
Up to this point, nothing actually happens except for the task graphs are set up. Now it’s time actually kicking off the computation by calling .compute()
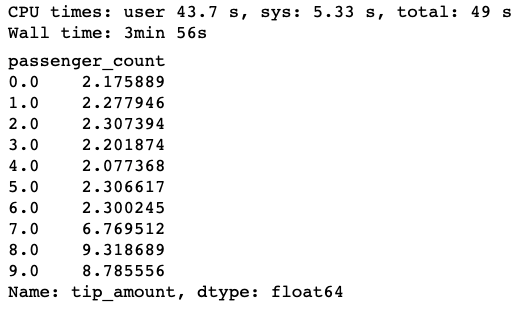
%%time
mean_tip_amount = df.groupby("passenger_count").tip_amount.mean()
mean_tip_amount.compute()
Go to Cloud
To take advantage of the free tier Coiled cluster service I will benchmark the performance on the Cloud there. Let’s do the same thing on the 10-worker cloud.
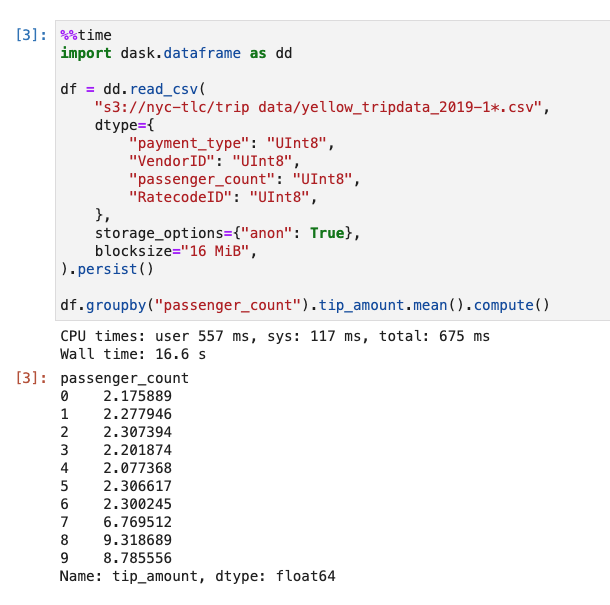
Astoundingly it reduces to wall clock time from 4min 34s to merely 16.6s, just adding a few extra lines of code to your original Pandas codes. Of course this performance estimate is pretty crude. Actually there is tons of room to improve the raw Pandas way such as only reading the columns that you need.
Using dask.delayed to parallelize custom computations
You can parallelize custom algorithms using the dask.delayed interface. This allows one to create graphs directly with a light annotation of normal python code. Let’s check out the following simple example.
import dask
import random
import pandas as pd
import time
class Example():
def __init__(self):
pass
def _q1(self, x):
return random.randint(1,100)/x
def _q2(self, x):
return random.normalvariate(x, 1)
def _apply_q1(self, q):
return pd.DataFrame([q]*10)
def _apply_q2(self, q):
return pd.DataFrame([q*0.5]*10)
def agg(self, x):
df1 = self._apply_q1(self._q1(x))
time.sleep(10)
df2 = self._apply_q2(self._q2(x))
time.sleep(10)
return None
class ExampleDask(Example):
@dask.delayed
def agg(self, x):
return super().agg(x)
if __name__ == '__main__':
xs = [10,20]
# test the non-parallel way
tic = time.perf_counter()
e = Example()
output = []
for x in xs:
output.append(e.agg(x))
toc = time.perf_counter()
print(f"Non-parallel computation finishes in {toc - tic:0.1f} seconds")
# test the parallel way
tic = time.perf_counter()
e = ExampleDask()
output = []
for x in xs:
output.append(e.agg(x))
dask.delayed()(output).compute()
toc = time.perf_counter()
print(f"Dask delayed parallel computation finishes in {toc - tic:0.1f} seconds")
What it returns:
Non-parallel computation finishes in 40.0 seconds
Dask delayed parallel computation finishes in 20.0 seconds
It clearly shows the efficiency benefit (2X) that modifying only single one line of code!